Graceful shutdown using Simple Sytems Manager and Terraform on AWS
Automate all the things
At TabMo, we slowly but surely move our services from Jenkins to GitlabCI and automate all the things that can be thanks to blue/green deployments with Terraform or docker images for integration tests. Our goal is to reduce human checks, or SSH connections as much as possible.
We encounter a problem for slow-terminating app such as reporting app, slow means on AWS 1min30 😅. These apps can be killed too quickly for them to safely process their data. It forced us to SSH to our instances to stop them via a systemctl stop service when we had to deploy new code or if we wanted to reduce our number of instances in ASGs. It also means no automated ASG scale-in when our traffic peak are over, and force us to pay for some servers that we do not need anymore 💸
CircleCI has done a great job explaining how to set up Auto Scaling Groups (ASG), Auto Scaling Lifecycle Hooks, and SQS Queues to manage how to gracefully shutdown slow terminating apps. This blog article focus on what to do after our SQS queue has received a lifecycle hooks message from an ASG.
Using a Lambda and Systems Manager
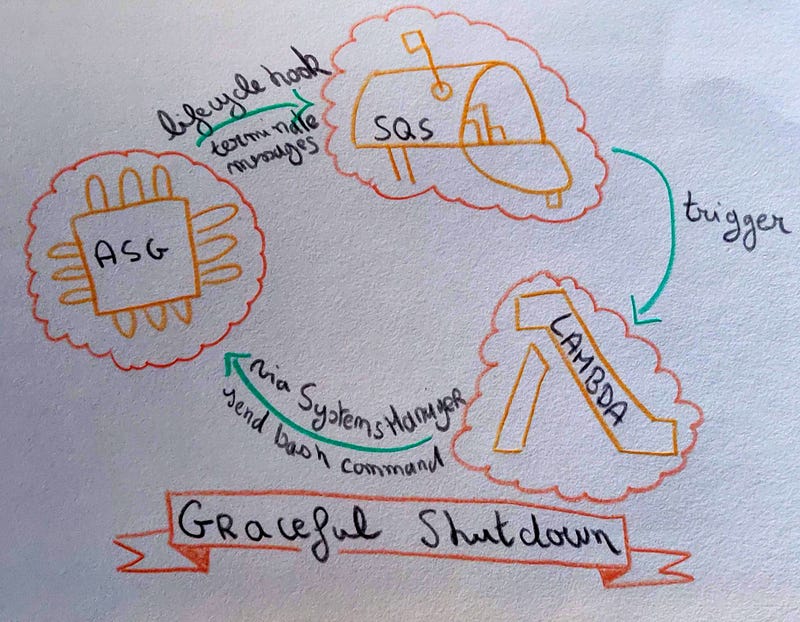
To send a bash command to remote servers we chose to use AWS Systems Manager and AWS Lambda. This lambda is triggered when a Lifecycle hook message is received by a SQS queue. These messages come from our Auto Scaling Group when a instance is on its way to be terminated.
Lambda
Step one is to parse SQS messages. We check if this is a terminating event from our service, then delete the message from the SQS queue, to avoid infinite loop in case something goes wrong. Finally our lambda sends a bash command to the targeted instances, the instance ID to terminate is inside the Lifecycle hook message, via System Manager installed by default on our ASG instances.
To perform System Manager commands on our instances, we have to give the right permissions to our app:
resource "aws\_iam\_role\_policy\_attachment" "app\_ssm\_attach" _{_ role = "_${_aws\_iam\_role.app.name_}_"
policy\_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
And the right permissions for our Lambda:
resource "aws\_iam\_policy" "lambda-ssm-asg" _{_ name = "lambda-ssm-asg-_env_"
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": \[
{
"Effect": "Allow",
"Action": \[
"ssm:SendCommand"
\],
"Resource": \[
"arn:aws:ssm:\*::document/AWS-RunShellScript",
"arn:aws:ec2:\*:account:instance/\*"
\]
}
\]
}
EOF
_}_
After these permissions set, we can use this python function to send bash command to our ASG’s instances
Trust, but verify
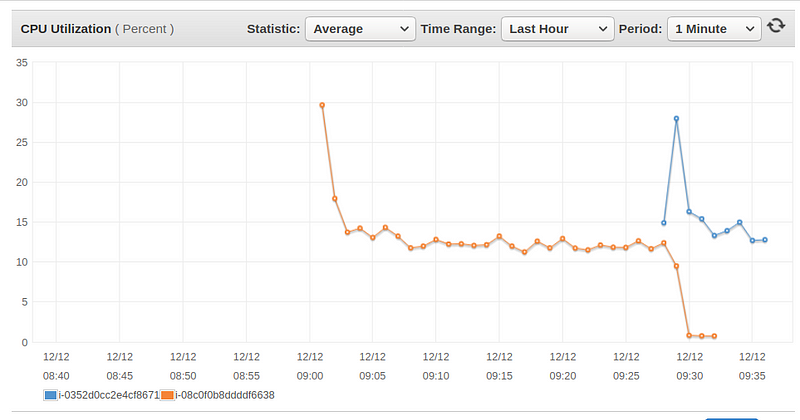
To check that our Lambda does what it supposes to do, we can check on the EC2 console that our previous instance (in orange) has completed its last job before shutting down or check on our logging system for a graceful shutdown log 🐕
Scaling policy
To complete this new architecture, we can set a scaling policy based on a CloudWatch low cpu alert to only use what we need in term of infrastructure and save money on our AWS bills.
resource "aws\_autoscaling\_policy" "app-scale-in" _{_ name = "app-scale-in"
scaling\_adjustment = -1
adjustment\_type = "ChangeInCapacity"
cooldown = 900 # 30 minutes
autoscaling\_group\_name = "_${_aws\_autoscaling\_group.app.name_}_"
_}_
resource "aws\_cloudwatch\_metric\_alarm" "app-low-cpu" {
alarm\_name = "app-low-cpu-alert"
comparison\_operator = "LessThanThreshold"
evaluation\_periods = "6" # 30min
metric\_name = "CPUUtilization"
namespace = "AWS/EC2"
period = "300" # 5 minutes
statistic = "Average"
threshold = "40"
dimensions = _{_ AutoScalingGroupName = "_${_aws\_autoscaling\_group.app.name_}_"
_}_
alarm\_description = "Low CPU alert"
alarm\_actions = _\[_"_${_aws\_autoscaling\_policy.app-scale-in.arn_}_"_\]
_}
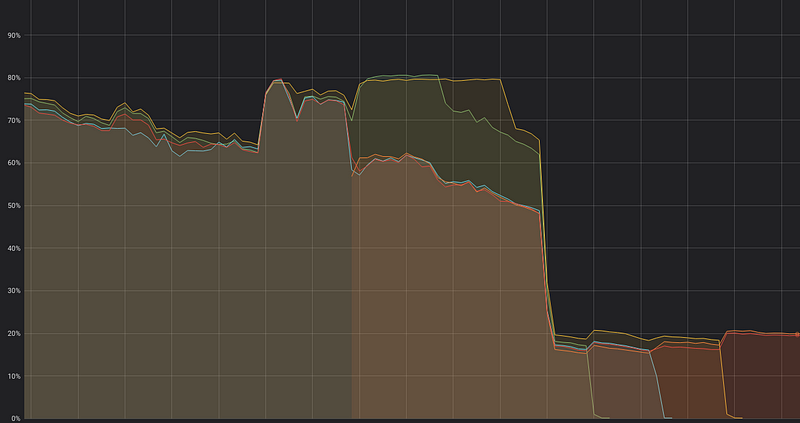
This scale in policy will gracefully shutdown instances every 30 minutes, our cooldown period, when all instances’ CPU inside the ASG is below 40% for 30 minutes 📉
And voilà, we fully automated our deployment for our slow terminating apps, we can now save time and money 😄
Special thanks
Ian Davis for your article about graceful shutdowns
Tom Elliff for your answer on Stackoverflow
Chloe Pellen for showing me that I could draw 😁
And of course, TabMo’s Yann Blancard, Joakim Ribier, Dương Khánh Chương, and Julien Lafont ✊